Claude's 1M Token Context Window Is GA. RAG Isn't Dead — It Got Better.
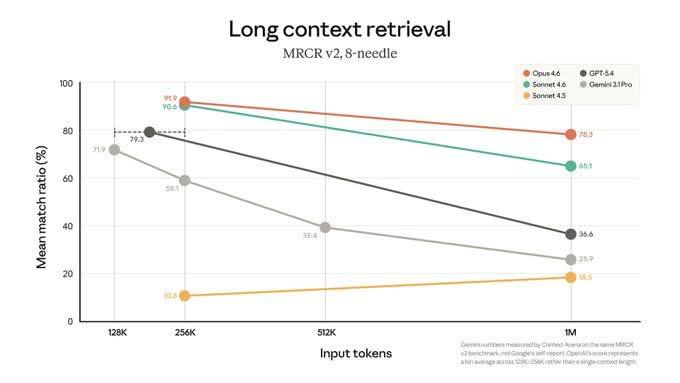
Anthropic just made 1M token context windows generally available for Claude Opus 4.6 and Sonnet 4.6. The announcement buried a number that should make every AI developer stop and think: on MRCR v2 — the toughest long-context benchmark — Opus 4.6 hits 78.3% retrieval accuracy at 1 million tokens. Claude Opus 4.6 actually improves slightly going from 128K to 1M tokens — from 71.9% to 78.3%. Competitors collapse: GPT-5.4 drops from ~80% to 36.6%, Gemini 3.1 Pro hits 18.5%, Sonnet 4.5 (the previous generation) falls to 25.9%.
That’s not a small gap. That’s a different category of capability.
But the question I keep seeing in my feed is wrong. It isn’t “does this kill RAG?” The right question is: when does each approach actually win?
What just happened
MRCR v2 (Multi-Range Context Retrieval) tests whether a model can accurately retrieve specific facts buried at different positions in a very long document — the kind of needle-in-a-haystack retrieval that matters for real-world long-context tasks. Passing MRCR v2 well means the model genuinely processes the full context, not just the beginning and end.
At 1M tokens, most models collapse. Their recall drops by 25–36% from their peak. Opus 4.6 holds at 78.3% — roughly 2x better than the next best model at the same context length.
That’s remarkable. And it’s now on every plan.
What the benchmark chart actually shows is more striking than the headline number. Most models peak around 128K–256K and then fall off hard. GPT-5.4 drops from ~80% at 128K to 36.6% at 1M — a 54% collapse. Gemini 3.1 Pro is already at 10.8% at 128K (functionally broken for long-context). Sonnet 4.5 falls from 59.3% to 25.9%. But Opus 4.6? It goes from 71.9% at 128K to 78.3% at 1M. It improves as the context grows. That’s a qualitatively different architecture, not just a bigger number.
The “RAG is dead” argument is wrong
Every time a context window gets bigger, someone declares RAG obsolete. It hasn’t been true at 32K. It wasn’t true at 200K. It won’t be true at 1M.
Here’s the math that gets ignored:
Cost: Processing 1M tokens with Claude Opus costs roughly $15–30 per request. A RAG call with good embeddings + reranking retrieves the relevant 5–10K tokens at roughly 5–15 cents. That’s a 100–200x cost difference per query.
Latency: A full 1M token pass takes 30–60+ seconds. A RAG retrieval + generation pass takes 1–3 seconds. For any interactive or real-time use case, that latency is disqualifying.
Recall quality: A well-tuned RAG pipeline with strong embeddings and a reranker achieves 70–85% recall on the chunks that actually matter — already competitive with Opus’s 78.3% on the full corpus, at a fraction of the cost.
For most production use cases, RAG still wins on the economics.
When long-context actually wins
That said, the 1M window unlocks real new capabilities that RAG genuinely can’t replicate:
One-shot corpus analysis. Review an entire codebase, contract library, or clinical trial dataset in a single pass. No chunking decisions, no retrieval errors from poor embeddings, no information lost at chunk boundaries. When you need to reason across the whole thing at once — long-context is the right tool.
Complex reasoning over dense documents. Some questions can’t be answered by retrieving the top-k relevant chunks. They require synthesizing relationships across hundreds of passages. “What are all the inconsistencies in this contract?” is a long-context question. “What does section 12.3 say?” is a RAG question.
Small knowledge bases used infrequently. If your entire knowledge base fits in 200K tokens and you only query it a few times a day, just stuff it in. The overhead of a RAG stack isn’t worth it.
The hybrid is the answer
The best systems don’t choose — they route.
This is what we built with soul-agent: an auto query router that classifies each incoming question and sends it to the right path.
- ~90% of queries → RAG: “What did we decide about the API design?” — precise, fast, cheap
- ~10% of queries → RLM (exhaustive): “Summarize everything you know about my relationship with this client over the past year” — synthesis, needs the full picture
The 1M context window makes the RLM path dramatically more accurate and practical than it was six months ago. That’s not a threat to the RAG architecture — it’s an upgrade to one half of the system.
What this means for developers
A few practical implications:
Don’t rebuild your RAG pipeline. Long-context is a complement, not a replacement. Keep your RAG for the interactive, high-frequency queries. Add a long-context path for the synthesis and one-shot analysis tasks.
Reranking matters more now, not less. As context windows grow, the quality of what you put in them becomes more important. A 1M token context with garbage retrieval is still garbage. A strong reranker that surfaces the right 20K tokens is more valuable than ever.
Cost-aware routing is a first-class concern. If you’re not routing queries by cost tier, you will burn budget fast. The economics of a well-routed hybrid system vs. naive long-context for everything are 50–100x different.
Opus 4.6 for synthesis, Sonnet 4.6 for retrieval. Anthropic is signaling the right use pattern with their own model lineup — use the best model where it matters, the faster/cheaper one where it doesn’t.
The bottom line
Claude’s 1M GA is a genuine capability leap. 78.3% MRCR at 1M tokens, while competitors drop by a third — that’s not marketing, that’s a measurable engineering achievement.
But it doesn’t change the fundamental economics of production AI. RAG is fast, cheap, and precise. Long-context is thorough, expensive, and slow. The right architecture uses both — and routes intelligently between them.
Your RAG pipeline is fine. Now it has a better partner.
Building persistent memory for LLM agents? Check out soul-agent — RAG + RLM hybrid retrieval, pip install soul-agent.